


Concurrent Execution and Query Throughput in Databricks SQL

Introduction
While discussing concurrent query execution in Databricks SQL (DBSQL) with customers, I noticed a common misconception that I’d like to demystify in this blog. Databricks recommends a cluster for every 10 concurrent queries. This often sounds too low for customers with hundreds of analysts running BI dashboards containing dozens of queries each. With only 10 concurrent queries per cluster, can DBSQL truly support high-concurrency workloads? The answer is yes, and here’s how.
Definitions
Let’s start by defining two important concepts:
Concurrent Query Execution refers to the number of queries that can run simultaneously on a SQL warehouse. It is constrained by compute resources, workload complexity, and system-enforced concurrency limits.
Query Throughput measures the total number of queries processed over a given period (e.g., queries per hour, per minute, or per second). It depends on query execution speed, warehouse size, and workload optimization.
For example, if an isolated BI dashboard with 20 queries takes one minute to refresh, the throughput is 20 queries per minute (QPM). When 20 queries are submitted simultaneously, only about 10 of them will start executing immediately, while the other 10 may wait in a queue. In this case, concurrent query execution is 10, but it can be increased dynamically through autoscaling.
Concurrency Limits
Databricks recommends a cluster for every 10 concurrent queries. The maximum number of queries in a queue for all SQL warehouse types is 1,000 [1].
At first glance, 10 concurrent queries per cluster may seem low, especially when compared to Online Transaction Processing (OLTP) workloads, where processing many thousands of queries per second (QPS) is common. However, OLTP queries are relatively simple—they retrieve a "needle in a haystack" using optimized indexes. In contrast, Online Analytical Processing (OLAP) queries scan, process, and aggregate large datasets, requiring more compute resources.
Concurrency throttling is not unique to Databricks SQL; Snowflake, Redshift, BigQuery, and other cloud data warehouses enforce similar concurrency limits to prevent system overload. Both OLTP and OLAP databases implement query queuing to manage workloads efficiently.
Scaling Concurrency
DBSQL dynamically provisions compute resources (clusters) to increase concurrency. When new capacity is added, queued queries are automatically routed to the new compute resources [1].
The minimum and maximum cluster limits for autoscaling are configurable. For example, for workloads requiring 20 to 50 concurrent queries, setting Min = 2 and Max = 5 helps minimize queuing delays. Additionally, increasing the SQL warehouse size often improves query execution speed, leading to higher throughput.
The figures below illustrate the impact of SQL warehouse scaling on BI dashboard execution in DBSQL. In the first figure, with autoscaling settings Min = 1 and Max = 2, execution starts on one cluster, and after some queries get queued, DBSQL quickly adds another cluster. This setup demonstrates how DBSQL dynamically provisions additional compute resources to handle increased concurrency. In the second figure, the warehouse with a fixed cluster count Min = 2 and Max = 2 demonstrates that execution takes place on two clusters from the start, which avoids query queueing completely.
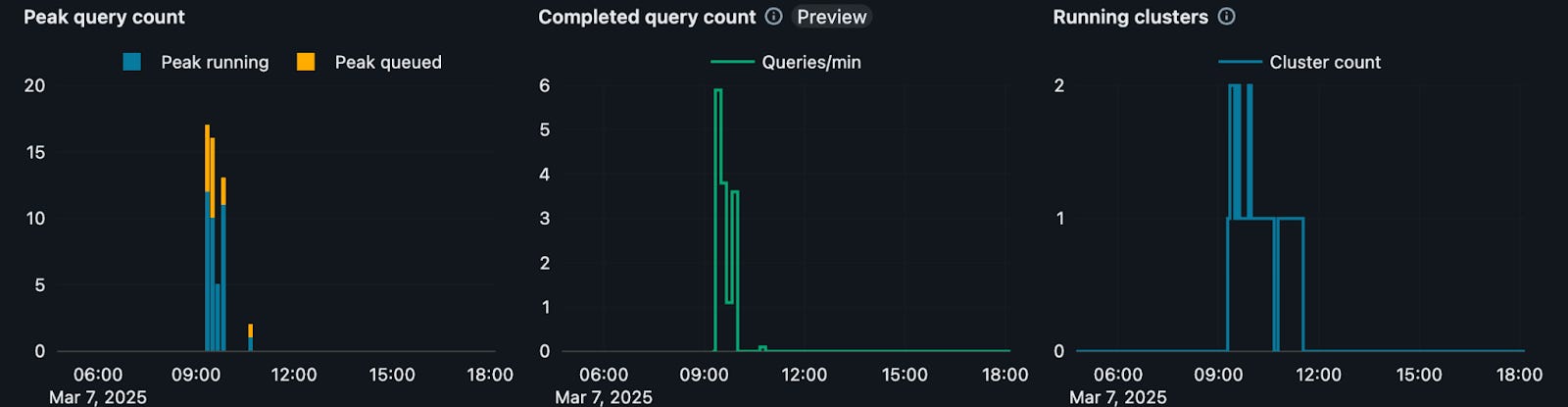
Figure 1: BI Dashboard Execution on DBSQL Large Min = 1 Max = 2
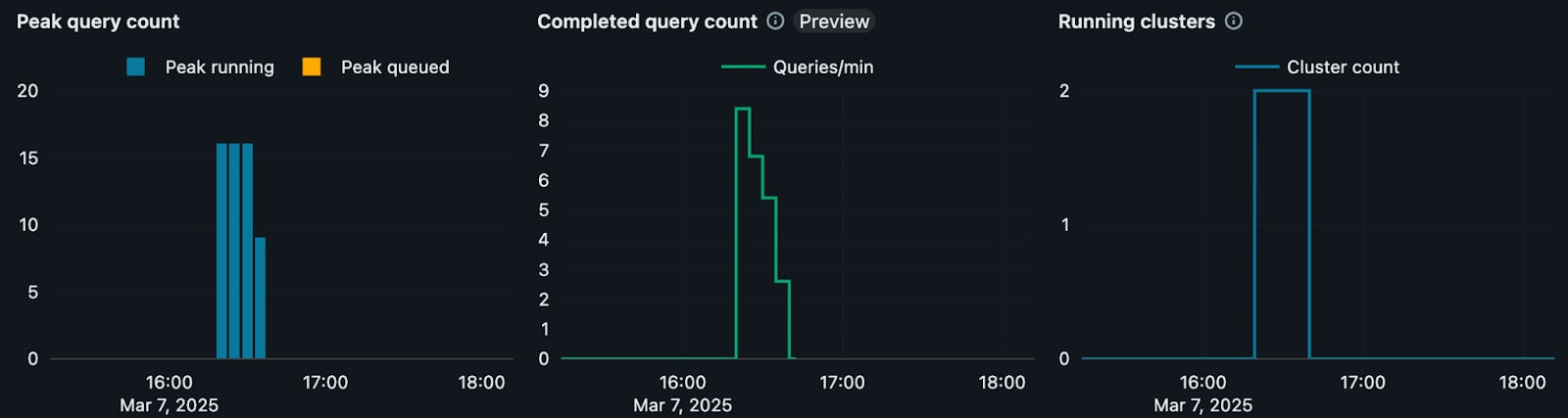
Figure 2: BI Dashboard Execution on DBSQL Large Min = 2 Max = 2
It is worth noting that, for Pro and Classic SQL warehouses, scaling is not instant, as it takes time to spin up new clusters. For Serverless SQL warehouses, scaling is near-instantaneous as resources are allocated from a pre-provisioned pool, eliminating startup delays. Serverless also has an advantage of Intelligent Workload Management (IWM), which predicts resource demands and adjusts capacity accordingly. Over time, IWM learns to make smarter decisions about scaling, ensuring efficient workload distribution and minimized latency.
Query Throughput and Performance Benchmarks
Here are two fully audited benchmarks that are available in the public domain since 2021. As of today, internal performance benchmarks indicate even higher throughput, though specific numbers cannot be disclosed.
Benchmark 1: Small-Scale Workloads
In 2021, DBSQL processed 14,777 TPC-DS queries per hour (QPH) on a 10GB dataset using a DBSQL Large warehouse without autoscaling [2].
To put this into perspective, if each BI dashboard refresh consists of 20 queries, then 14,777 / 20 = 738 dashboards can be refreshed per hour. In real-world scenarios, many of these dashboards and queries are likely to be served from the results cache, further increasing throughput and reducing compute resource consumption.
This demonstrates DBSQL’s efficiency for high-concurrency analytical workloads over small datasets, which are common in multi-tenant environments.
Benchmark 2: Large-Scale Workloads
In 2021, Databricks set an official world record by processing 32,941,245 queries per hour on a 100TB dataset using a DBSQL 4X-Large warehouse without autoscaling [3].
Following the same example, if each dashboard refresh consists of 20 queries, then 32,941,245 / 20 = 1,647,062 dashboards can be refreshed per hour.
The QphDS metric, used in the TPC-DS benchmark, represents the performance of mixed workloads. This essentially translates to nearly 33 million queries per hour, making DBSQL one of the most efficient solutions for large-scale analytical workloads.
Conclusion
By understanding and leveraging DBSQL’s concurrency management and scaling capabilities, organizations can efficiently support high-concurrency, high-throughput workloads. Properly sizing SQL warehouses, configuring autoscaling, and optimizing query execution strategies ensure timely and reliable analytical query processing, even for large-scale workloads. Whether handling dozens or millions of queries per hour, DBSQL provides one of the most efficient and scalable solutions available today.
References
[1] SQL Warehouse Sizing, Scaling, and Queuing Behavior
[2] New performance improvements in Databricks SQL
[3] Databricks Sets Official Data Warehousing Performance Record